


Locking Deep Dive - 1
Multiprocessing Semaphore의 실체를 파헤쳐보기



애플리케이션을 개발할 때, "locking"은 데이터의 일관성과 동시성 제어를 위해 중요한 역할을 한다. 여러 사용자가 동시에 애플리케이션을 사용할 때, 데이터가 일관되게 유지되도록 하는 것이 매우 중요하다. 이를 위해 많은 개발자들이 다양한 locking 메커니즘을 사용한다.
Locking의 기본 원리는 간단하다. 특정 코드 블록이나 데이터에 대한 접근을 제한하여 동시에 여러 스레드나 프로세스가 해당 자원을 사용하지 못하게 하는 것이다. 이렇게 함으로써 데이터가 예기치 않게 변경되거나 손상되는 것을 막을 수 있다. 스레드가 1개인 경우에는 크게 이슈가 없을 수도 있지만, 여러 스레드가 동시에 작업을 수행하거나, 여러 프로세스가 같은 자원을 공유해서 사용해야 하는 경우에 locking은 매우 중요한 역할을 한다.
Python에서는 Multiprocessing 라이브러리에서 다양한 Locking 기능을 제공한다. Lock, RLock, Semaphore, Condition, Event 객체 등이 바로 그것이다. 기능은 조금씩 다르지만, 내부적으로는 기본적으로 Semaphore(세마포어)를 활용하고 있다.
그래서 이번에는 Semaphore를 통해서 Locking 과정의 실체를 알아보고자 한다.
Semaphore(세마포어)
Semaphore(세마포어) 클래스는 Python의 multiprocessing 모듈에서 제공하는 동기화 도구로, 여러 프로세스가 공유 자원에 접근할 수 있는 최대 개수를 제한하는 역할을 한다. 세마포어는 주로 병렬 프로그래밍에서 경쟁 조건을 피하고 자원의 접근을 제어하는 데 사용된다.
세마포어는 내부적으로 카운터를 가진다. 이 카운터는 세마포어의 초기 값으로 설정되며, 자원에 접근할 수 있는 최대 프로세스 수를 나타낸다. 세마포어는 두 가지 주요 연산을 제공한다.
acquire(): 세마포어의 카운터 값을 감소시킨다. 카운터가 0이면, 세마포어가 해제될 때까지 대기한다.
release(): 세마포어의 카운터 값을 증가시킨다. 카운터가 증가하면, 대기 중인 다른 프로세스가 접근할 수 있게 된다.
세마포어 클래스를 보면, 내부적으로 SemLock 객체를 상속받아서 사용한다. 전체 구현을 보면, 사실상 SemLock만 사용하는 거라고 봐도 과언이 아니다.

기본적으로 Lock은 1개의 스레드만 진입을 허용하는 데 사용된다. 다만, 세마포어의 경우에는 여러 스레드가 일정 수만큼 lock을 획득할 수 있도록 value를 동적으로 받는다. 즉, Lock은 값이 1인 세마포어인 셈이다.
세마포어는 내부적으로 SemLock 객체를 생성할 때 SEMAPHORE라는 타입을 지정한다. 다른 타입으로는 RECURSIVE_MUTEX가 있다.
RECURSIVE_MUTEX는 재귀적 뮤텍스로, 같은 스레드가 여러 번 lock을 획득할 수 있는 뮤텍스이다. 이는 특정 스레드가 이미 lock을 획득한 상태에서 다시 lock을 요청할 때 deadlock이 발생하지 않도록 설계되었다. 예컨대, 현재 수행하고 있는 스레드가 다른 함수를 호출하면서 다시 lock을 요청하는 경우에 유용하게 사용할 수 있다. 즉, RECURSIVE_MUTEX은 Reentrant lock(재진입 가능한 lock)을 구현할 때 사용하는 값이다.
SemLock 클래스 코드를 보면 다음과 같다.
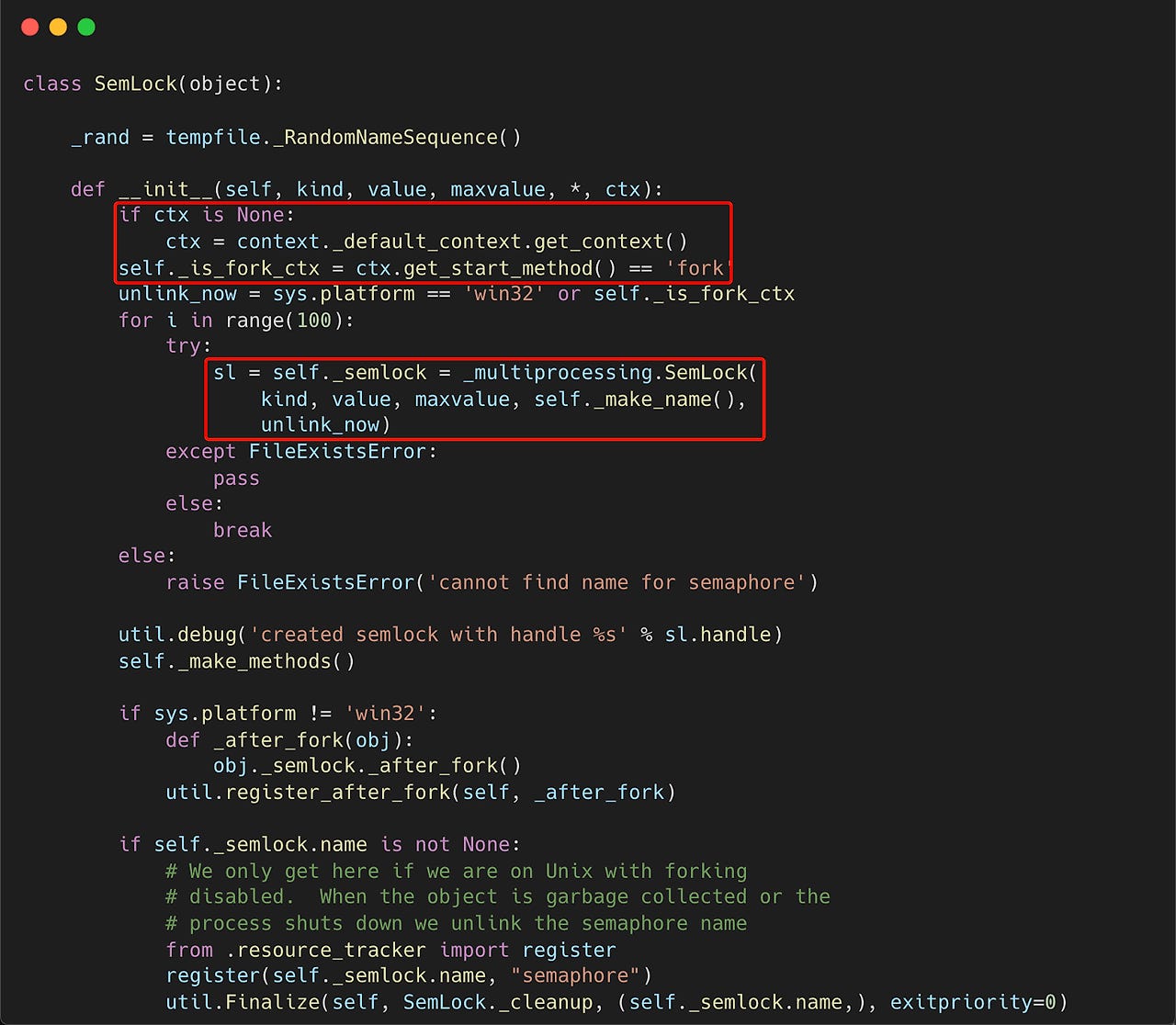
먼저, 멀티프로세싱에 대한 Context(콘텍스트)를 만든다. 아무런 콘텍스트 객체가 주어지지 않으면, 기본 콘텍스트를 사용한다. 기본 콘텍스트에서는 프로세스 생성에 대한 방식을 정하게 된다. 프로세스 생성을 할 수 있는 방법은 다음과 같이 3가지가 존재한다.
1. Spawn 방식
spawn 방식은 새로운 파이썬 인터프리터를 시작하고, 부모 프로세스의 객체들을 자식 프로세스로 복사하는 방식이다. 이는 Windows와 macOS에서 기본적으로 사용되는 방식이다. spawn 방식은 안전하지만, fork 방식보다 상대적으로 느릴 수 있다. 새로운 파이썬 인터프리터를 시작하기 때문에 자식 프로세스는 초기 상태에서 시작하며, 부모 프로세스의 상태를 복사하지 않는다. 다양한 플랫폼에서 일관되게 동작하고, 특히 스레드가 많은 프로그램에서 안전한 방식으로 간주된다.
2. fork 방식
fork 방식은 부모 프로세스를 복제하여 자식 프로세스를 생성하는 방식이다. 이는 Unix 계열 운영체제(Linux, macOS 등)에서만 사용할 수 있다. fork 방식은 빠르지만, 여러 스레드를 사용하는 프로그램에서 안전하지 않을 수 있다. 부모 프로세스의 주소 공간을 그대로 복사하여 자식 프로세스는 부모 프로세스의 실행 상태를 이어받는다. 이는 자식 프로세스가 부모 프로세스와 같은 메모리를 공유하게 되며, 스레드와의 호환성 문제가 발생할 수 있다.
3. forkserver 방식
forkserver 방식은 부모 프로세스가 별도의 서버 프로세스를 시작하고, 이 서버 프로세스가 자식 프로세스를 fork 방식으로 생성하는 방식이다. 이는 Unix 계열 운영체제에서 사용할 수 있다. forkserver 방식은 fork 방식의 장점(빠름)과 spawn 방식의 장점(안전함)을 일부 결합한 방식이다. 별도의 서버 프로세스를 통해 자식 프로세스를 생성하며, 서버 프로세스는 한 번만 생성되고 이후 요청을 처리한다. 서버 프로세스는 새로운 자식 프로세스를 fork 방식으로 생성하므로, 스레드와의 호환성이 fork 방식보다 더 좋다.
기본적으로 채택되는 프로세스 시작 방식은 운영체제에 따라 다르다. Windows에는 fork라는 개념이 없기 때문에, fork/forkserver 방식으로 프로세스를 만들 수가 없다. 그래서 Windows라면, 기본으로 spawn 방식을 사용한다. Unix 기반이라면, 기본적으로 fork를 사용하는데, 그중 MacOS는 spawn 방식을 사용한다.
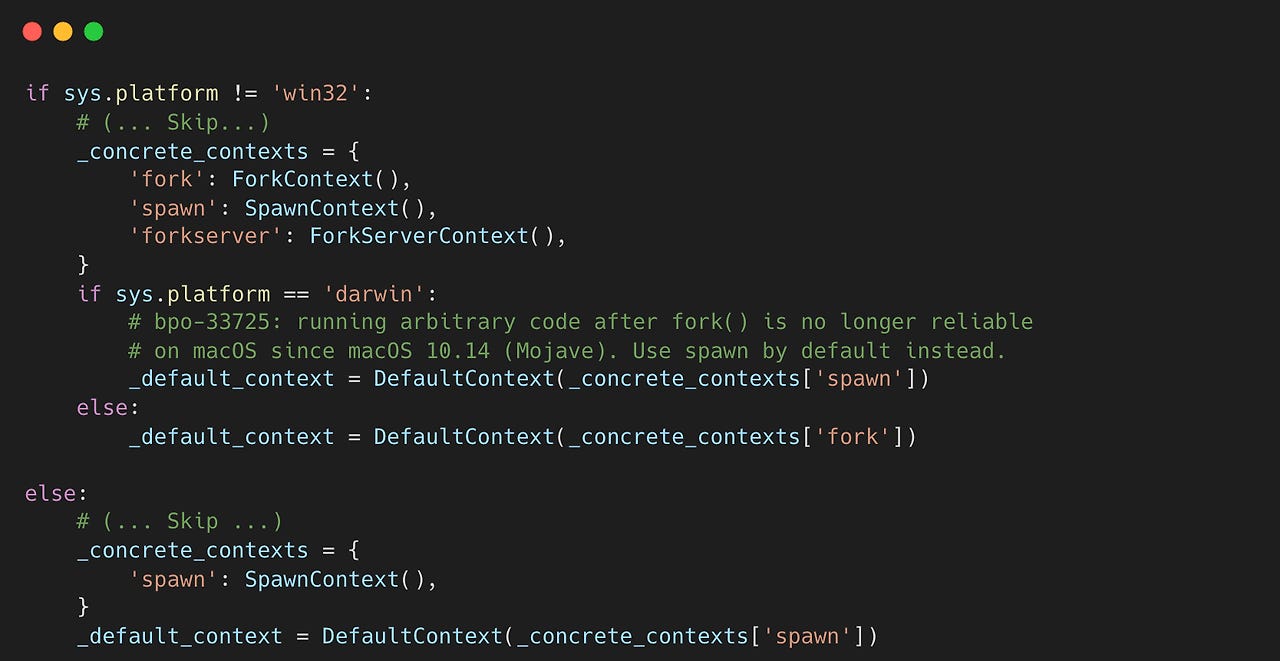
기본 콘텍스트를 생성하고 나면, 결국 저수준은 OS기반 SemLock 구조체를 사용한다. self._semlock에 저수준의 SemLock 객체를 저장해 놓고, acquire/release 함수도 모두 저수준 multiprocessing API를 사용하도록 설정한다.

그러면 내부적으로 acquire/release는 어떻게 구현되어 있는지 살펴보자.
Acquire 과정
acquire() 함수는 cpython 중 _multiprocessing_SemLock_acquire() 함수에 구현되어 있다. 해당 함수에서는 내부적으로 _multiprocessing_SemLock_acquire_impl() 함수를 호출한다. 실제 Lock을 획득하고, Count를 늘리는 부분이 여기에 구현되어 있다.
먼저, sem_trywait을 통해서 GIL을 해제하지 않고도 lock을 잡을 수 있는지 확인한다. 파이썬이 실제로 코드를 수행하기 위해서는 GIL을 획득해야 하는데, 현재 코드를 수행 중인 상황에서 바로 세마포어를 획득할 수 있는지를 확인한다. 만약 획득 가능하다면, GIL 해제 없이 바로 다음 코드를 수행할 수 있기 때문이다.
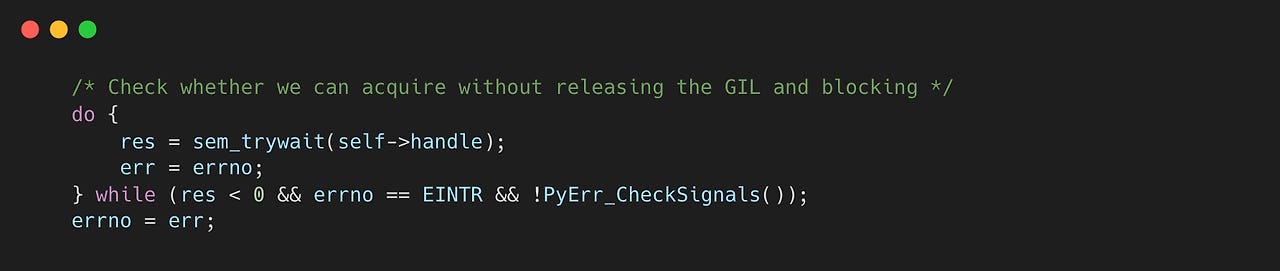
sem_trywait 함수는 glibc에 구현되어 있는데, 그 구현은 매우 간단하다. __sem_waitfast 함수에서 세마포어 Lock을 획득하고, 실패하면 EAGAIN 에러코드를 반환한다.
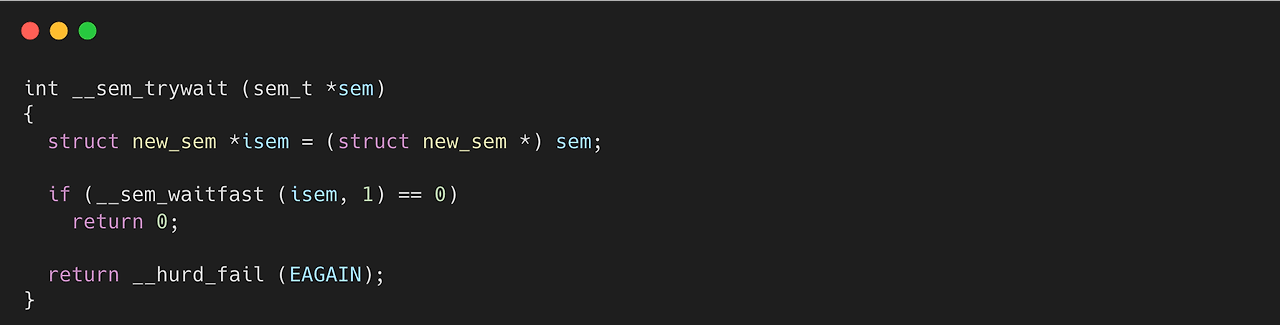
__sem_waitfast 함수를 보면 현재 세마포어 값(d)이 0인 경우에는 -1을 리턴하도록 되어 있다. 즉, 이미 주어진 세마포어 수 이상으로 사용하면, __sem_trywait은 바로 -1을 리턴한다는 의미이다. 만약 0보다 크면, atomic 하게 현재값(d)을 d-1로 교체한다.

여기서 atomic_compare_exchange_weak_aquire 함수는 원자적으로 값을 변경하는 메커니즘이다. 값 자체를 변경할 때, 새로운 값이 있는 메모리로 교체하는 방식으로 Compare And Swap(CAS) 방식이라고도 한다.
CAS(Compare-And-Swap)는 병렬 프로그래밍에서 동시성을 제어하기 위한 중요한 원자적 연산이다. CAS 연산은 특정 메모리 위치의 값이 예상된 값과 일치하는지 비교하고, 일치하면 새로운 값으로 교체하는 작업을 수행한다. 이 연산은 동시에 여러 스레드가 동일한 메모리 위치에 접근할 때 발생할 수 있는 경쟁 조건을 방지하는 데 사용된다.
(참고)
Strong CAS는 비교와 교환 연산이 성공할 때까지 계속 반복하여, 결국에는 성공하도록 보장한다. 이는 비교 시점에서 값이 변하지 않았는지를 확인하며, 변하지 않았다면 값을 교환한다. 값이 변했을 경우, 다시 시도하는 방식으로 동작한다. Strong CAS는 항상 성공하거나 실패 여부를 정확하게 판별하므로 신뢰성이 높다. 이는 대개 무한 루프를 통해 값을 교환할 때까지 반복적으로 시도하는 방식으로 구현된다.
Weak CAS는 비교와 교환 연산이 실패할 경우, 반복을 하지 않고 즉시 종료할 수 있다. 이는 일시적인 실패가 빈번하게 발생하는 상황에서 사용된다. Weak CAS는 실패 시 즉시 종료할 수 있는 특성 때문에 성능이 더 나을 수 있지만, 반드시 성공하지 않을 수 있다. 주로 스핀락(spinlock)이나 무한 루프 없이 재시도 메커니즘을 사용하는 상황에서 사용된다.
세마포어에서는 자체적으로 실패 시, 재시도를 하기 때문에 Weak CAS를 사용한 것으로 보인다. 만약 파이썬처럼 GIL이 존재하는 언어에서, Lock을 획득하다가 다시 Lock에 걸리는 상황이 발생하면 GIL을 해제하지도 못하고 계속 Block 되는 현상이 발생할 수 있다.
다시 aquire 과정으로 돌아가보자. 앞서 설명한 sem_trywait 과정에서 만약 EAGAIN 에러와 함께 -1을 반환받으면, 아직 Lock을 획득하지 못한 셈이다. 따라서, 다음과 같이 획득하기 위한 로직을 반복한다.
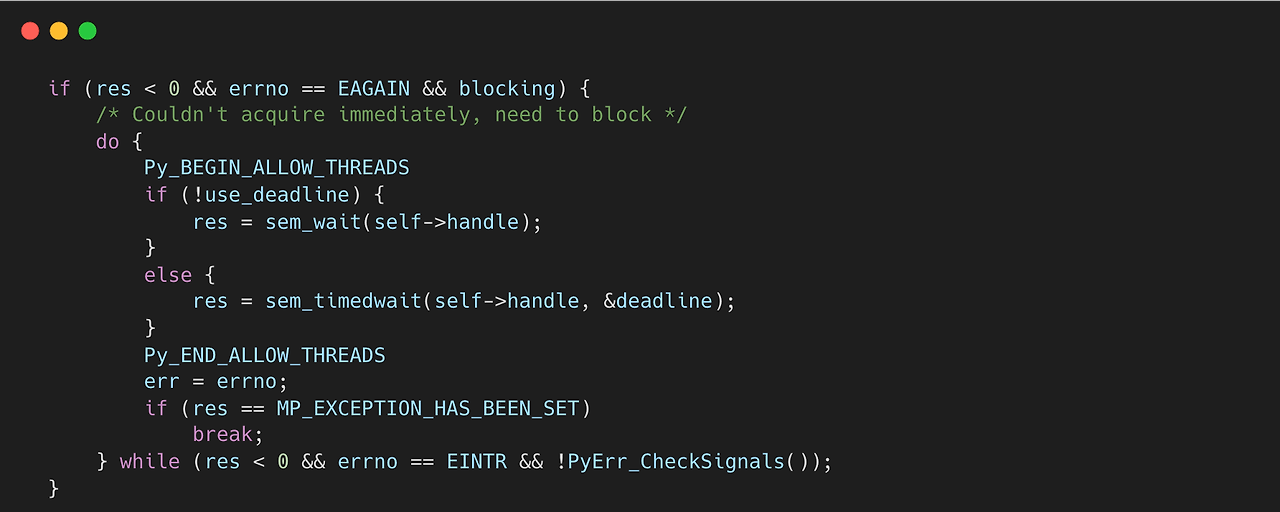
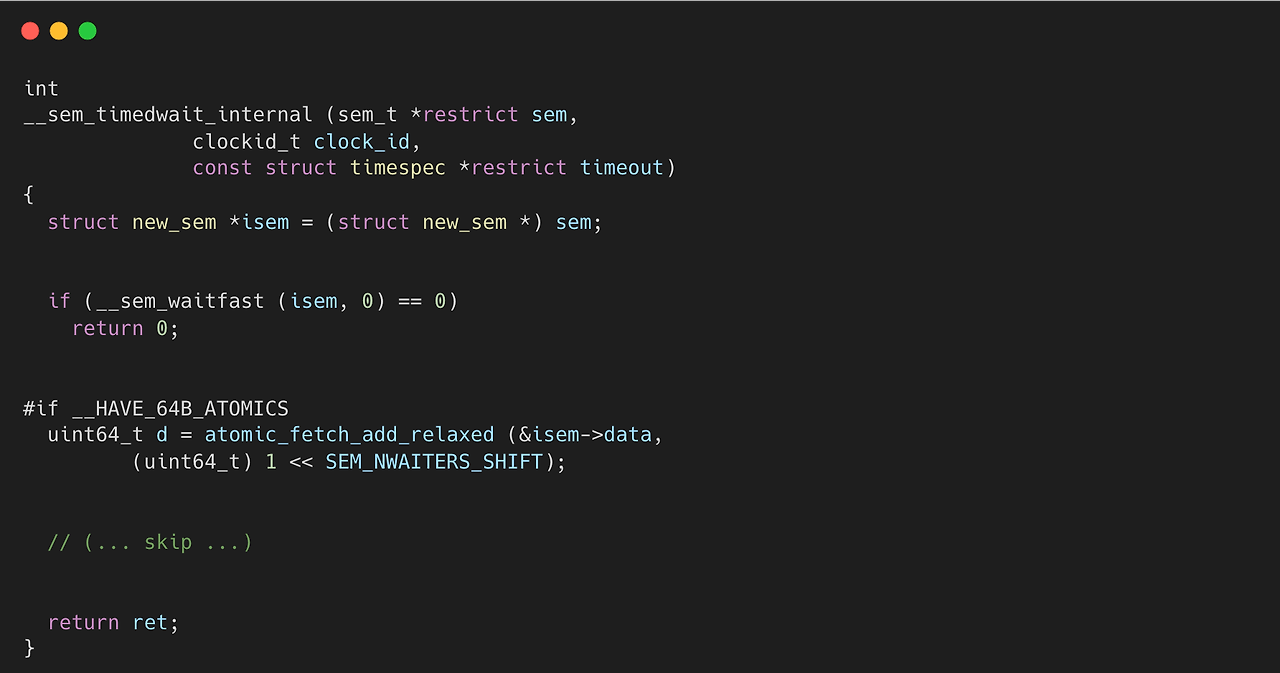
여기서 sem_wait 함수는 내부적으로 __sem_timedwait_internal 함수를 호출한다. 해당 함수를 간략하게 확인해 보면, 먼저, 앞서 확인했던 __sem_waitfast 함수를 통해 lock을 획득한다. 만약 실패하면 현재 isem->data에 (uint64_t) 1 << SEM_NWAITERS_SHIFT 값을 추가한다. 이 과정은 현재 대기 중인 스레드를 표시해 주기 위해 사용한다. 나중에 release 과정에서 해당 값을 통해 대기 중인 스레드가 있는지를 확인한다.
여기서 한 가지 중요한 건, sem_wait 함수를 부르기 전에 Py_BEGIN_ALLOW_THREADS을 통해서 GIL을 해제하는 과정을 거친다는 점이다. 파이썬은 Blocking IO 과정을 거치기 전에 GIL을 해제한다. 그 이유는 Blocking IO 작업이 끝나기 전까지 다른 스레드가 GIL을 획득하여 명령어를 수행할 수 있기 때문이다. sem_wait/sem_timedwait 함수도 내부적으로 Blocking IO 작업이 수반된다. Lock을 획득하지 못하면, 아예 glibc 자체에 interruption 기반의 Blocking 작업을 수행한다.

Py_BEGIN_ALLOW_THREADS 은 내부적으로 _PyEval_ReleaseLock을 호출한다.
만약 Lock을 획득하는 과정이 끝나면 Py_END_ALLOW_THREADS를 통해 다시 GIL을 획득한다. 여기서 함정은 GIL을 획득하기 위해서는 또다시 세마포어를 획득해야 한다는 점이다. GIL 자체가 글로벌 Lock이기 때문이다.

Py_END_ALLOW_THREADS는 내부적으로 _PyEval_AcquireLock을 호출한다.
이렇게 acquire 과정을 모두 거치게 되면, 비로소 프로세스는 Critical Section(CS)에 접근할 수 있게 된다.
이번에는 반대로 release 과정을 살펴보자.
Release 과정
Release() 함수는 cpython 중 _multiprocessing_SemLock_release 함수에 구현되어 있고, 내부적으로는 _multiprocessing_SemLock_release_impl 함수를 호출한다.
만약에 타입이 RECURSIVE_MUTEX이면 count값을 줄이고 바로 반환한다.

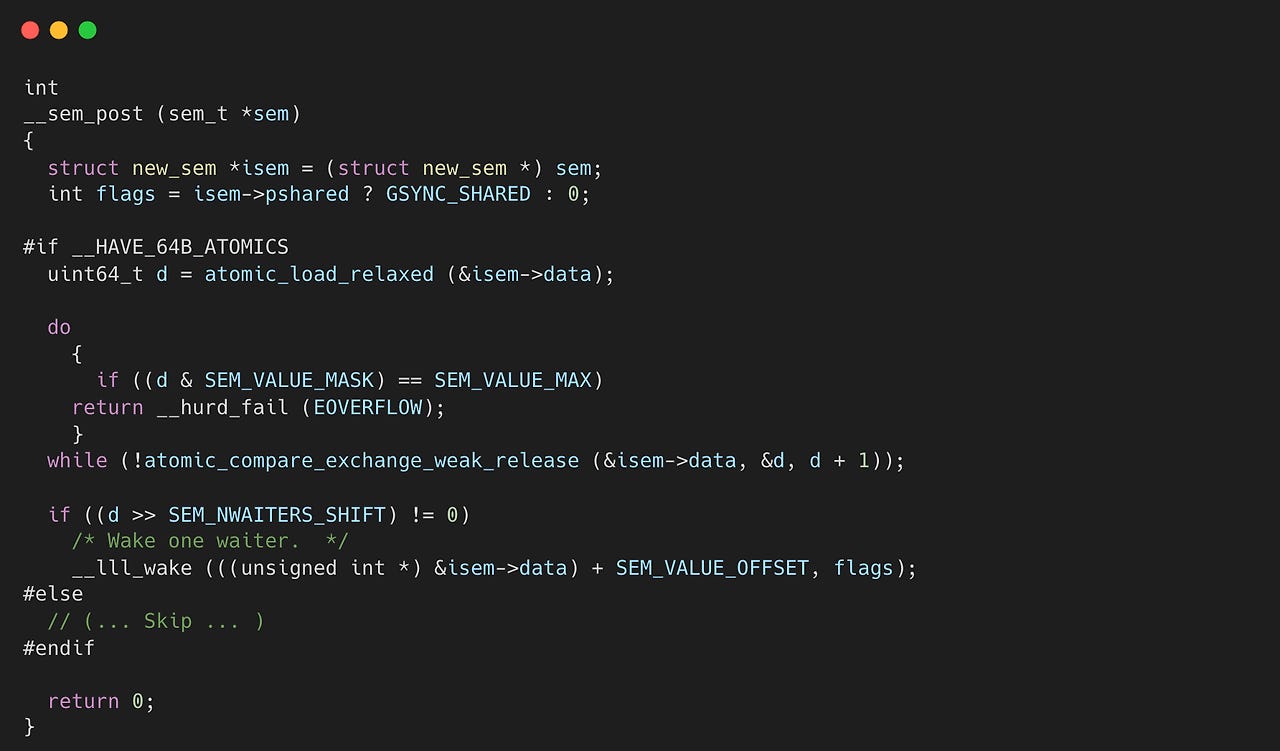
만약 SEMAPHORE이면 sem_post 함수를 통해서 Lock을 반환한다.

glibc의 __sem_post 함수를 보면 atomic_compare_exchange_weak_release 함수를 통해서 lock을 해제하는 과정을 거친다. 여기서는 앞선 acquire 과정과는 다르게 while 문을 통해 release가 될 때까지 계속 시도한다. 해제하는 과정을 마치면, 대기 중인 스레드가 있는지를 확인한다. 만약 대기 중인 스레드가 있다면, 그중 하나를 깨운다. 그러면 앞서 aquire 과정에서 interrupt를 받기 전까지 대기하던 스레드들 중에 하나가 깨어나서 lock을 획득하게 된다.
요컨대, Python의 multiprocessing Lock은 세마포어를 기반으로 설계되었으며, 세마포어는 내부적으로 cpython의 semLock이라는 구조체를 사용한다. Lock을 획득하고 해제하는 과정은 CAS를 통해서 값을 원자적으로 변경하는 과정을 거친다. Lock을 획득할 때는 첫 시도에서는 GIL을 해제하지 않고 시도하지만, 첫 실패 이후에는 GIL을 해제하고 나서, Lock 획득 과정을 수행한다. 만약 다른 스레드에서 해제 과정을 거치고 대기 중인 스레드 중 하나에 interrupt를 보내주면, 대기 중인 스레드는 비로소 Lock을 획득한다. Lock을 획득한 스레드는 GIL 획득을 위해 다시 한번 대기를 하고, GIL을 획득하고 나서야 비로소 다음 코드를 수행할 수 있다.