
ArgoCD Sharding Method


argocd-application-controller는 ArgoCD에서 애플리케이션의 상태를 확인하고 Out Of Sync 인 경우에 필요한 조치를 수행해 주는 역할을 한다. 현재 상태에 대한 정보를 확인함과 동시에 코드에 대한 변경사항도 함께 봐야 하다 보니, 부하가 크게 발생하는 컴포넌트 중 하나이다. ArgoCD 애플리케이션 수가 많다면, 분명 1개의 레플리카로는 한계가 생길 수도 있다.
ArgoCD는 이런 상황을 대비하기 위해 HA(High Availability)를 지원한다. 일반적인 Stateless 한 애플리케이션과는 달리 application-controller은 기본적으로 Stateful 한 성격을 지니고 있다. 그래서 기본 설정을 사용하면 Deployment가 아니라 Statefulset으로 생성된다.
그래서 단순하게 Replicas 값만 변경한다고 해결되는 구조는 아니다. 일단 공식 홈페이지 설명을 보면 Replica를 늘림과 동시에 ARGOCD_CONTROLLER_REPLICAS라는 환경변수를 수정해주어야 한다.

문제는 replica를 생성하게 되면, 기본적으로 샤딩(Sharding)이 발생한다. 여기서 샤딩은 전체 Argocd가 Sync 해야 하는 클러스터 및 애플리케이션을 application-controller replica 별로 분산시키는 것을 의미한다. 즉, HA라고 하지만 실제로는 Active/Active, Active/Standby 구조가 되는 것은 아니라는 의미이다.
그러면, 여기서 ArgoCD application-controller가 말하는 샤딩은 어떤 방식으로 이루어질까?
Sharding Method
먼저 application-controller를 실행하면 다음과 같이 GetClusterSharding()이라는 함수가 호출된다. 해당 함수에서는 replicaCount를 환경변수로부터 가져오는데, 그게 ARGOCD_CONTROLLER_REPLICAS이다. 즉, spec.replicas를 늘린다고 하더라도, 환경변수를 추가하지 않으면, application-controller는 replica가 늘어났다고 판단하지 않는다.
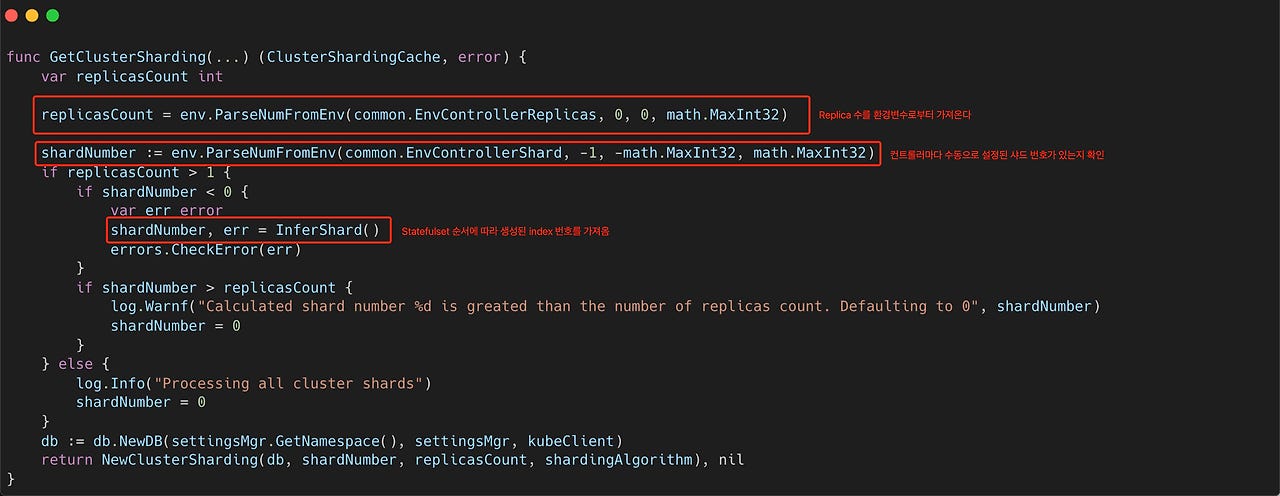
만약 replicaCount가 1보다 크다면, 자신의 샤드 번호를 찾는 과정을 거친다. 환경변수를 통해서 지정할 수는 있지만, 만약 아무런 설정이 없으면 Hostname에서 끝 번호를 사용한다. 즉, Statefulset 규칙에 맞게 생성된 번호에 따라서 자신의 샤드 번호를 지정한다. 다음의 InferShard() 함수가 바로 해당 기능을 구현한 코드이다.

이렇게 자신의 샤드 번호를 정하고 나면, 이제 샤딩 알고리즘을 정한다. 이전에 불러왔던 replicaCount 값이 1보다 크면 자동으로 GetDistributionFunction을 호출한다.
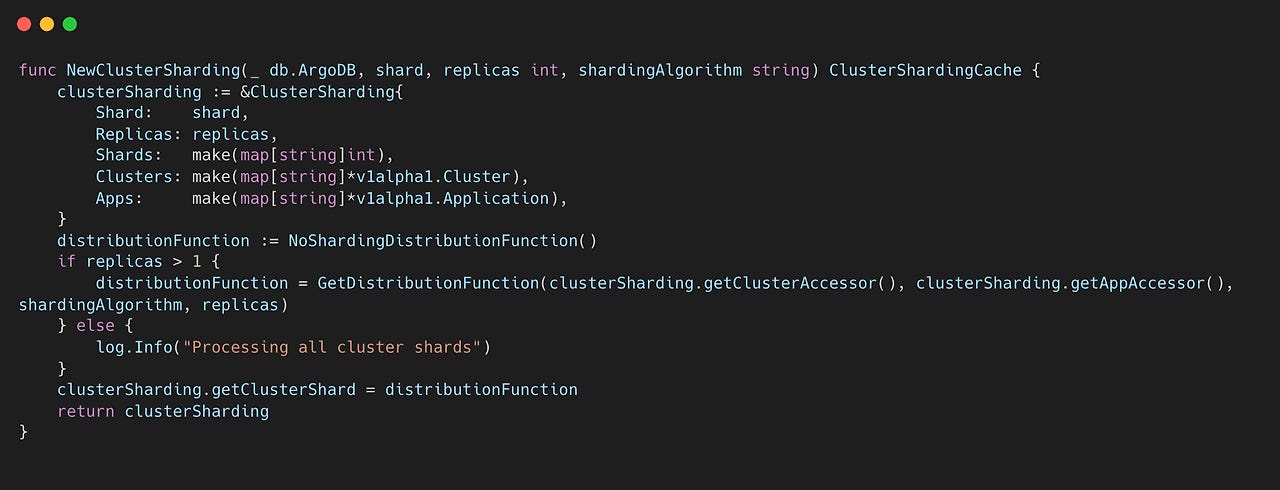
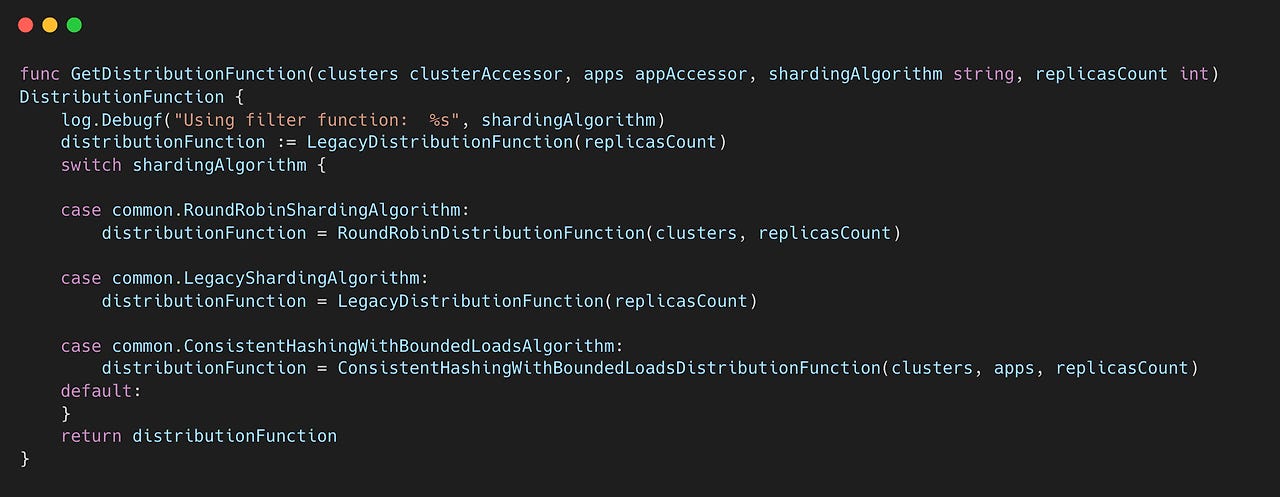
GetDistributionFunction() 함수를 보면, shardingAlgorithm 값이 따라서 다음과 같이 세 가지로 분류된다. 참고로, shardingAlgorithm 값은 ARGOCD_CONTROLLER_SHARDING_ALGORITHM 환경변수를 ㅗ통해서 설정할 수 있다.
legacy: hash 값을 기반으로 작업을 분배하는 알고리즘 (기본값)
RoundRobin: 여러 샤드가 순차적으로 하나씩 작업을 분배받아서 평등하게 분배하는 방식
ConsistentHashing: Consistent Hashing을 기반으로 replica 수가 변경되더라도 resharding이 덜 발생하도록 분배하는 방식(아직 정식 출시 안됨)
Hash는 클러스터의 ID를 FNV-1a 해싱으로 값을 구한 후, replicaCount로 나눈 나머지가 해당 클러스터의 샤드가 된다. Hash 값은 ID가 변경되지 않는 한 변경되지 않으므로, 각 replica가 담당하는 샤드는 지속적으로 고정된다. 또한 Hash 알고리즘 특성상 분배가 일정하지 않을 수 있다. 만약 여러 application-controller 파드 중 하나가 제대로 동작하지 않으면, 해당 파드에 속한 클러스터의 애플리케이션들은 해당 파드가 정상 상태가 되기 전까지 싱크 되지 않을 수 있다.
반면 Round Robin은 클러스터를 순차적으로 리스트에 넣은 다음, 각 index를 replicaCount로 나눈 나머지가 클러스터의 샤드가 된다. 따라서 클러스터가 추가될 때마다, 다시 resharding이 발생한다. 왜냐하면, 내부적으로 ID를 기준으로 정렬한 후, 순차적으로 리스트에 추가하는데, 만약 ID가 리스트 중간에 들어가면, 뒷부분 클러스터들은 모두 샤드가 변경된다. 다만, Round Robin 특성상 모든 replica가 거의 균등하게 작업을 분배받을 수 있다.
Dynamic Distribution
위 방식의 공통 문제 중 하나는 Replica 수를 변경하면, 모든 replica 파드가 재시작한다는 점이다. 왜냐하면 환경변수를 통해서 Replica를 설정하기 때문이다. 만약 spec.replicas를 통해서 늘어나는 파드에 따라서 자동으로 샤딩을 하고 싶다면, dynamic-cluster-distribution-enabled 옵션을 추가하면 된다. 혹은 환경변수로 ARGOCD_ENABLE_DYNAMIC_CLUSTER_DISTRIBUTION 값을 true로 설정하면 된다. 참고로, 해당 기능은 statefulset이 아니라 deployment Kind를 사용해야 한다.
만약 Dynamic Distribution을 활성화하면, 먼저 실행된 replica가 replicaCount 수만큼 비어있는 매핑 리스트를 만들고, 이를 configmap에 저장한다. 그리고 각 replica들이 비어있는 공간에 자신의 hostname을 매핑해서 저장한다. 만약 replica를 추가하면, 매핑 리스트 크기를 늘려서 저장한다. 그리고 readiness probe가 10초에 한 번씩 configmap에 업데이트된 정보를 바탕으로 resharding 하도록 호출한다.
관련 자료
https://argo-cd.readthedocs.io/en/stable/operator-manual/high_availability/
https://argo-cd.readthedocs.io/en/stable/operator-manual/dynamic-cluster-distribution/