


Amazon Aurora
Amazon Aurora 데이터베이스에 대해 알아보자


Amazon Aurora는 AWS에서 제공하는 고성능 관계형 데이터베이스 서비스로, MySQL과 PostgreSQL을 기반으로 설계되었다. Aurora는 기존의 MySQL 및 PostgreSQL 데이터베이스와 호환되면서도, 성능과 가용성 면에서 획기적인 향상을 제공한다. Amazon Aurora는 클라우드 네이티브 설계로, 고가용성, 확장성, 데이터 보안, 자동 백업 등 다양한 기능을 포함하고 있어 데이터베이스 운영의 복잡성을 크게 줄여준다.
Amazon Aurora의 주요 장점 중 하나는 뛰어난 성능이다. Aurora는 표준 MySQL보다 최대 5배, 표준 PostgreSQL보다 최대 3배 더 빠른 성능을 제공한다. 이러한 성능 향상은 Aurora의 독자적인 아키텍처 덕분이다. Aurora는 스토리지와 컴퓨팅을 분리하여 각 노드가 독립적으로 확장될 수 있도록 설계되었다. 이는 데이터베이스의 읽기 및 쓰기 작업을 분산시켜 성능 병목을 최소화하고, 고성능을 유지할 수 있게 한다.
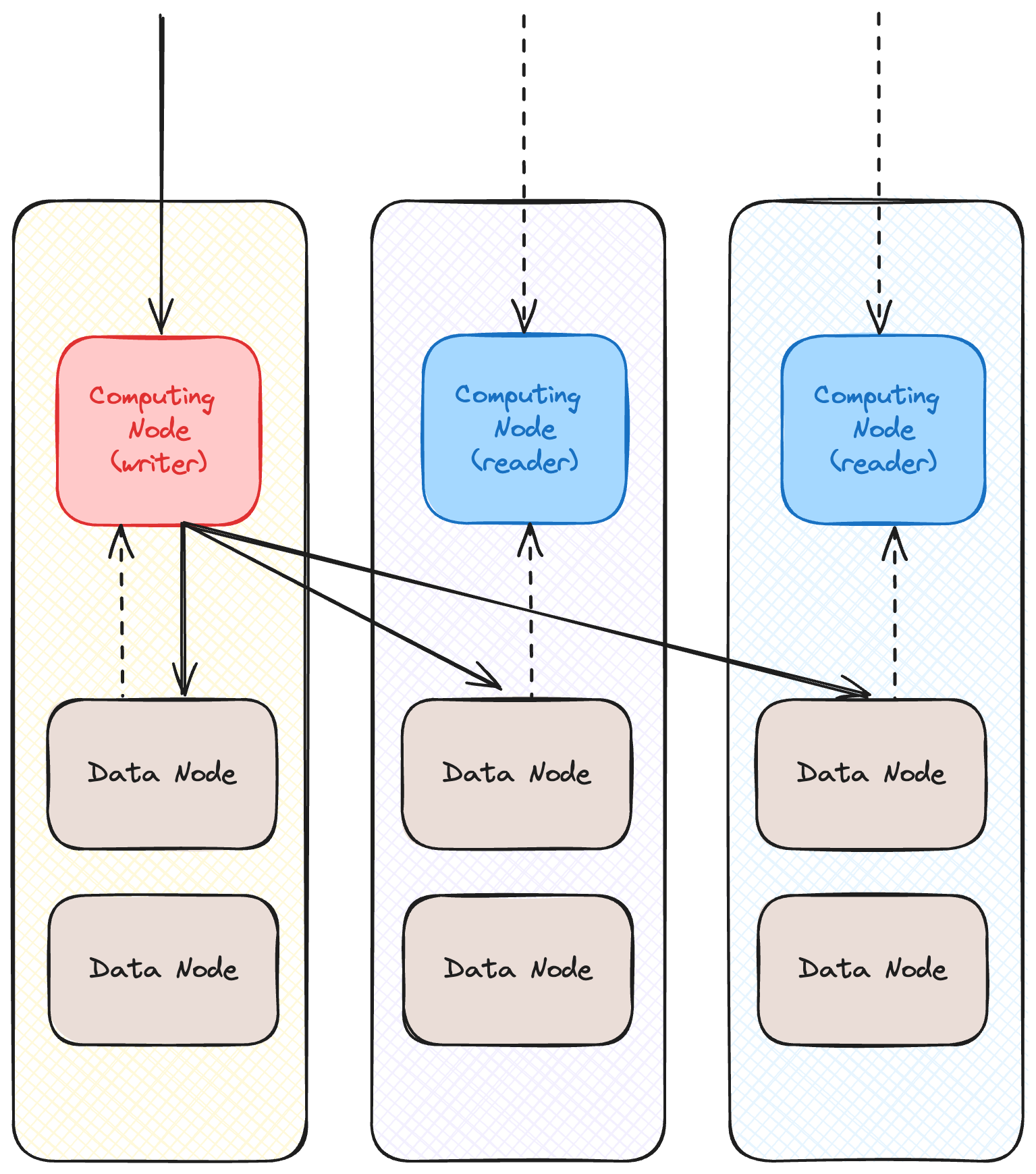
Aurora는 고가용성을 보장하기 위해 여러 가용 영역(AZ)에 걸쳐 데이터를 자동으로 복제한다. 기본적으로 6개의 복제본이 3개의 AZ에 걸쳐 저장되며, 이는 데이터 손실을 방지하고 장애 발생 시에도 데이터의 무결성을 유지할 수 있게 한다. Aurora는 장애 복구 시간을 몇 초 이내로 줄이는 자동 장애 조치(failover) 기능을 제공하여, 데이터베이스 가용성을 극대화한다. 이는 비즈니스 연속성을 유지하는 데 매우 중요한 역할을 한다.
또한, Aurora는 자동 백업과 특정 시점 복구(Point-In-Time Recovery, PITR)를 지원한다. 자동 백업은 Aurora 스토리지 계층에서 지속적으로 수행되며, 사용자는 데이터베이스를 특정 시점으로 복구할 수 있다. 이러한 기능은 데이터 손실에 대한 걱정을 덜어주고, 데이터베이스의 안정성을 높여준다. 백업은 Amazon S3에 안전하게 저장되며, S3의 높은 내구성과 가용성을 바탕으로 데이터가 안전하게 보호된다.
Aurora는 또한 읽기 성능을 향상시키기 위해 읽기 복제본(Read Replica)을 지원한다. 최대 15개의 읽기 복제본을 생성할 수 있으며, 이는 읽기 요청을 분산시켜 데이터베이스의 읽기 성능을 극대화할 수 있다. 읽기 복제본은 주 데이터베이스와의 지연 시간이 매우 짧아, 실시간에 가까운 데이터 접근이 가능하다. 이는 대규모 애플리케이션에서 읽기 작업이 집중될 때 매우 유용하다.